When and how should multiple imputation be used for handling missing data in randomised clinical trials – a practical guide wi
Background Missing data may seriously compromise inferences from randomised clinical trials, especially if missing data are not handled appropriately. The potential bias due to missing data depends on the mechanism causing the data to be missing, and the a
bmcmedresmethodol.biomedcentral.com
Abstract
- 무작위 임상 시험에서 데이터가 누락되면 시험 결과의 유효성이 떨어짐
- 잠재적 편향 (the bias potential)을 최소화하기 위해 누락된 데이터를 처리하는 최적의 방법을 찾고자 함
- best-worst and worst-best sensitivity analyses(민감도 분석), multiple imputation(다중 대치법), full information maximum likelihood 등을 설명함
Background
- 결측값 유형에는 MCAR(missing completely at random), MAR(missing at random), MNAR(missing at not random) 3가지가 있다.

- 관찰된 데이터로는 MAR과 MNAR을 구분하기 어렵다?
- MAR에서 multiple imputation, full information maximum likelihood 등의 방법은 unbiased한 결과를 만듦
- 그러나 MAR이라는 가정은 임상적으로 그럴듯하지 않을 수 있기 때문에 MNAR에서 sensitivity analyses 수행?
Methods to handle missing data
- 유명 의학 저널에 발표된 무작위 임상 시험의 95%가 결과 데이터가 누락된 것으로 보고됨
- 1차 분석에서 missing data를 처리하기 위해 complete case analysis(=delete 방법)를 가장 많이 사용하고 그 다음으로 single imputation, model-based methods, multiple imputation을 사용했다고 함
- complete case analysis(=delete)
- missing value가 있으면 삭제하여 missing value가 없는 데이터로(=observed data)만 분석
- MCAR인 경우, complete case analysis는 샘플 사이즈가 줄어들기 때문에 통계적 검정력이 저하되지만 observed data는 편향되지 않는다.
- MCAR이 아닌 경우, 이익은 과대평가하고 피해를 과소평가할 위험이 있다.. ? - single imputation
- 단일 대체는 missing value를 마지막 관측값 또는 평균값.. 과 같은 값으로 대체
- missing value에 대한 비현실적인 가정에 의존하기 때문에 변동성과 잠재적 편향이 과소평가될 수 있음. - multiple imputation
- 다중 대체는 무작위 임상 시험에서 유효한 일반화 된 방법이며 모든 데이터 유형에 사용할 수 있다.
다중 대체를 사용하지 않는 이유들
즉, complete case analysis만으로 충분한 경우
- complete case analysis는 다음 3가지 경우에 유효하다.
- 누락된 데이터가 5% 미만이고 누락된 데이터의 영향이 미미한 경우
- 만약 위 경우인지 의심이 된다면 best-worst and worst-best case sensitivity analyses를 수행 - 종속 변수에만 결측 값이 있고 보조 변수가 식별되지 않는 경우
- 보조 변수는 결측치가 있는 변수와 관련이 있지만 회귀 분석에 사용되지 않는 변수
- 다중 대체를 사용하면 그로 인해 야기되는 불확실성 때문에 표준 오차가 증가할 수 있음 - 위에서 언급한 것처럼 데이터가 MCAR이라는 것이 확실한 경우
- 그러나 MCAR인 것이 확실한 경우는 비교적 드물고, MCAR이라는 가설을 Little’s test로 테스트할 수 있지만 별로 중요하지 않은 방법?으로 판정된 이 테스트를 기반으로 가정하는 것은 현명하지 않을 수 있다?
- 따라서 쉽게 MCAR이라는 가정을 하면 안됨
missing value의 비율이 매우 큰 경우
- 누락된 데이터를 처리하기 위해 다중 대체 또는 다른 방법을 사용하여 실험 결과가 확인된다는?(=확증적이라는) 인상을 줄 수 있지만 많은 양의 데이터가 누락된 경우(for example, more than 40%)에는 그 결과가 결정적인 것으로(=확증적인 것으로) 간주되어서는 안된다.
* confirmative (확증적) : 실험 결과가 가설 또는 이론을 확인하거나 뒷받침하는 능력 의미
MCAR, MAR 가정이 유효하지 않은 것 같다?
- MAR 가정이 타당하지 않은 것처럼 보일 경우, missing value는 종속변수?와 관련이 있으며 결과가 편향을 가질 수 있음.
- 논문에서는 어떤 통계적 방법도 이러한 잠재적 편향을 확실하게 고려할 수 없다고 하며 누락된 데이터를 통계적 방법으로 처리하더라도 여전히 편향 위험이 있다고 함
- MCAR, MAR 가정을 만족하지 않으면 MNAR이라고 볼 수 있고, 결측치 처리에 사용되는 방법의 유효성을 보기 위해? best-worst and worst-best sensitivity analyses을 한다?
- 즉, 누락된 데이터로 인해 무작위 임상 시험에서 발생할 수 있는 잠재적 편향과 누락된 데이터 처리에 따르는 어려움을 설명하고 있으며 민감도 분석을 사용하여 누락된 데이터를 처리하는 데 사용되는 방법의 불확실성과 한계를 해결할 것을 권장.
When and how to use multiple imputations
- 참고로 논문에서 설명하는 maximum likelihood 방법은 continuous 변수에만 적용 가능하다고 함
- 위 ‘다중 대체를 사용하지 않는 이유들’에 어느 것도 충족되지 않으면 다중 대체 사용
Different types of multiple imputation
- single value regression
- 종속 변수(dependent variable)만 결측치를 가지고 보조 변수가 있는 경우 (즉, 결과=종속변수와 상관관계가 있는 다른 변수가 있는 경우 그 값을 사용하여 종속 변수의 missing value를 추정할 수 있음)
- 다변량(multivariate)이 아닌 일변량인 경우인 듯 (잉… multiple imputation인 경우에 대한 설명인데…) - monotonic imputation
- monotonic missing
- 하나 이상의 변수에 누락된 값이 있을 경우, multiple imputation 사용하고 각 변수에 대해 한번에 결측값을 추정?하는 sequential regression imputation을 사용할 수 있음?
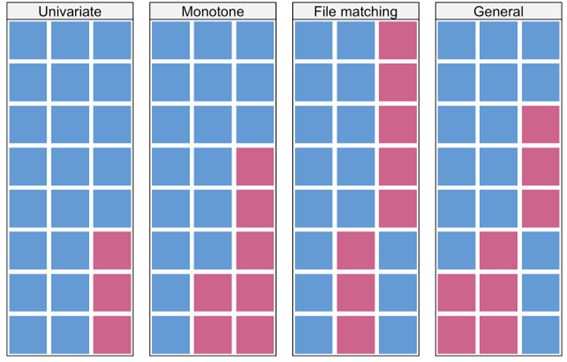
- chained equations or the Markov chain Monte Carlo (MCMC)
- monotone이 아닌 경우 사용