CBAM : Convolutional Block Attention Module
- paper
CBAM: Convolutional Block Attention Module
We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions,
arxiv.org
- code
GitHub - Jongchan/attention-module: Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convoluti
Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2018)" and "CBAM: Convolutional Block Attention Module (ECCV2018)" - GitHub - Jongchan/attention-module: Officia...
github.com
Abstract
- 중간 feature map이 주어지면 모듈은 ‘Channel’과 ‘Spatial’이라는 두 개의 개별 차원을 따라 어텐션 맵을 순차적으로 추론한 다음 adaptive feature 개선을 위해 어텐션 맵을 input feature map에 곱한다.
- 따라서 중요한 기능에 집중하고, 불필요한 기능 억제
Related work
- NETWORK ENGINEERING
- 대부분의 네트워크 엔지니어링 방법은 깊이, 너비, cardinality를 대상으로 하는 반면, 우리는 인간 시각 시스템의 흥미로운 측면 중 하나인 ‘attention’에 집중한다.
*cardinality
더보기딥러닝에서의 "cardinality"는 네트워크 구조에서 사용되는 개념으로, 특정 레이어에서의 그룹 또는 채널 분할 수를 나타냅니다. 이것은 특히 ResNet 및 EfficientNet과 같은 일부 신경망 아키텍처에서 사용되는 용어입니다.
cardinality 개념은 주로 컨볼루션 레이어에서 사용되며, 해당 레이어의 입력 채널을 여러 개의 그룹으로 분할하는 방법을 나타냅니다. 예를 들어, cardinality 값이 1인 경우 입력 채널은 하나의 그룹으로 분할되지 않고 전체 채널이 한 그룹으로 구성됩니다. 반면에 cardinality 값이 더 큰 경우, 입력 채널은 여러 그룹으로 분할됩니다. 이 그룹들은 서로 다른 필터를 사용하여 독립적으로 작동하고, 그 결과를 결합합니다.
이러한 cardinality 개념을 사용하는 이유는 다양한 그룹 간의 상호 작용을 통해 네트워크의 표현력과 학습 능력을 향상시키기 위해서입니다. cardinality를 늘리면 각 그룹은 더 작은 차원에서 작업하므로 매개 변수 및 계산 요구 사항이 줄어들게 됩니다. 이는 모델의 효율성을 향상시키면서도 복잡한 특징을 학습하는 데 도움이 될 수 있습니다.
따라서 cardinality는 네트워크 구조의 일부로 사용되는 파라미터이며, 입력 채널을 그룹으로 분할하여 효과적인 특징 학습을 달성하는 데 도움을 줄 수 있습니다. - ATTENTION MECHANISM
- 3D attention 맵을 바로 계산하기 보다는 채널 어텐션, 공간 어텐션으로 별도 학습한다. 분리된 어텐션 생성 프로세스는 훨씬 가벼움
Convolutional Block Attention Module


*broadcast
"broadcast"란, 다른 크기의 텐서들 간의 연산을 가능하게 하는 메커니즘입니다. 간단히 말해, 크기가 다른 텐서들 간의 연산을 할 때, 작은 텐서를 큰 텐서와 동일한 크기로 "확장"하여 연산을 수행하는 것을 의미합니다.
예를 들어, 3x3 크기의 행렬 A와 스칼라 값인 2를 곱하고자 한다고 가정해봅시다. 이때, 행렬 A는 (3, 3) 크기를 가지고 있고, 스칼라 값 2는 (1, 1) 크기를 가지고 있습니다. 딥러닝 프레임워크에서는 broadcast 메커니즘을 사용하여 이 연산을 가능하게 합니다.
Broadcast는 작은 텐서를 큰 텐서와 동일한 크기로 확장시킵니다. 따라서, 스칼라 값 2를 (3, 3) 크기로 확장하여 다음과 같이 만들 수 있습니다:
· Channel Attention Module

- Channel attention은 input image에서 무엇(what)이 의미있는 것인지에 대해 집중
- 채널 어텐션을 효율적으로 계산하기 위해 input feature map의 공간 차원을 압축한다(Pooling). 공간 정보를 집계하기 위해 일반적으로 average pooling이 채택되었다.
- 논문에서는 또한 max pooling이 더 미세한 채널 별 attention을 추론하기 위한 ‘고유한 객체의 특징’에 대해서 다른 중요한 단서를 모은다고 주장함
→ 따라서 논문에서 average-pooling + max-pooling 모두 사용 (실험 결과로도 두 기능 모두 사용하는 것이 네트워크 표현력을 향상시킴을 확인함)
- 평균 풀링과 맥스 풀링 연산으로 피쳐맵의 공간 정보를 집계하여 두 개의 서로 다른 공간 context를 생성

- 위 두 descriptors는 공유 네트워크(shared MLP)로 전달되어 channel attention map(Mc)를 생성한다.
- 공유 네트워크는 하나의 은닉층이 있는 multi-layer perceptron(MLP)이다.
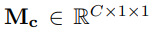
- Parameter overhead를 줄이기 위해 hidden activation size는 다음과 같다.
- r = reduction ratio
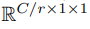
- 최종적으로 Channel attention module은 다음과 같은 식이 된다.

· Spatial Attention Module

- spatial attention은 어디(where)가 informative한 부분인지 집중, 채널 어텐션을 보완
- 채널 축을 따라 평균 풀링 및 최대 풀링 작업을 적용하고 concatenate하여 효율적인 feature descriptor를 생성(채널 축을 다라 풀링 작업 적용하면 정보 영역을 강조 표시하는 데 효과적)
- 위 연결된 feature descriptor에 convolution을 적용
- spatial attention map(Ms)을 생성하는 레이어는 강조하거나 억제할 위치를 인코딩한다
- 위 채널 attention 맵처럼 평균풀링과 맥스풀링연산으로 피쳐맵의 공간 정보를 집계하여 두 개의 2D 맵을 생성
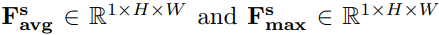
- 그런 다음 두 Fs들은 standard conv layer에 의해 연결되고 컨볼루션되어 2D spatial attention map이 생성된다.
- 최종적으로 Spatial attention module은 다음과 같은 식이 된다.
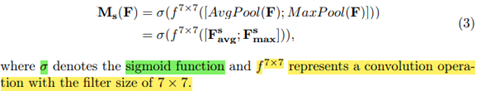
· Arrangement of attention modules
- input image가 주어지면, 두 Channel and spatial attention 모듈은 what 그리고 where에 초점을 맞춰 상호보완적으로 attention을 계산한다.
- 이를 고려하여 두 개의 모듈은 병렬 또는 순차적(sequential)으로 배치할 수 있다
- 논문에서는 sequential이 더 낫다고 함.
- 논문에서는 channel-first order가 spatial-first 보다 실험 결과가 낫다고 함
Results
- channel attention을 계산하는 효과적 접근 방법
- average pooling + max pooling 모두 사용했을 때, 더 미세한 추론 가능함을 실험적으로 확인 (이 실험에서는 channel attention module만 사용하고 reduction ratio는 16으로 고정)
- 두 풀링을 모두 사용할 때, 집계된 두 채널 features가 모두 동일한 의미적 임베딩 공간에 있기 때문에, attention 추론에서 매개변수를 저장하기 위해 shared MLP 사용. - spatial attention 을 계산하는 효과적 접근 방법
- spatial attention에서 avg&max pooling 또는 standard 1x1 conv를 사용하여 채널을 감소하는(generating the 2D descriptor) 방법을 비교했는데, avg&max pooling이 더 낫다.
- spatial attention은 다음 컨볼루션 연산에 대해 large kernel size of 7의 pooling을 사용하는 것이 가장 좋다. - 위 두 모듈을 결합하는 방법
- sequential, channel-first 방법이 the best-combining strategy
최종적으로 Our final module (ResNet50+CBAM) achieves top-1 error of 22.66%
Conclusions
Channel과 spatial이라는 고유한 모듈로 attention 기반 피쳐 개선을 적용하고, 오버헤드를 작게 유지하면서 상당한 성능 향상 달성